
This post is a follow up to Using ShiftLeft in Open Source, where I was looking to see if I could apply the principle of shift left testing to security. Now that ShiftLeft has a user interface, I want to come back to it and revisit looking at results from the UI instead of pouring through JSON reports. You’ll find that this write up parallels my original post so reading the original is not required to get up to speed.
Getting Rid of FUD and Panic
To get us started, allow me to go through the premise from my initial post: My long term goal is to formally insert security awareness into my development practices and eventually into my continuous integration-based builds.
After years of being involved in open-source development at Apache, we’ve seen security issues pop up in Apache Commons like arbitrary remote code execution, and denial of service attacks (CVE-2016-3092 and CVE-2014-0050). While some threats are real, other are just FUD. Even when they are real, it is important to consider context. There may be problems that end users never see because the “hole” is not reachable by users’ actions.
The idea behind ShiftLeft is to break old habits of building a product and then, later, figuring out how to fend off attacks and plug up security holes. Today, we take for granted that unit testing, integration testing, continuous integration, and continuous delivery are common place. ShiftLeft propose to make security analysis as ubiquitous.
By DonFiresmith (Own work) [CC BY-SA 4.0], via Wikimedia Commons
Getting Started
Since ShiftLeft is free for open source projects, I decided to look what it reports for Apache Commons IO, an Apache Commons Java component.
To get started, go to https://www.shiftleft.io/developers/ and enter a GitHub repository URL.
ShiftLeft then asks you for your name and email address:
And you are off to the races.
It’s important to note that ShiftLeft has a 30 day disclosure policy so you have plenty of time to fix up your FOSS projects.
My previous post looked at the 2.5 release tag for Apache Commons IO; here I am working with my GitHub fork of the master branch, which I’ve kept up-to-date. While my initial experiment with ShiftLeft gave me a 150 KB JSON report to pour over, here, I have a nice web UI to explore:
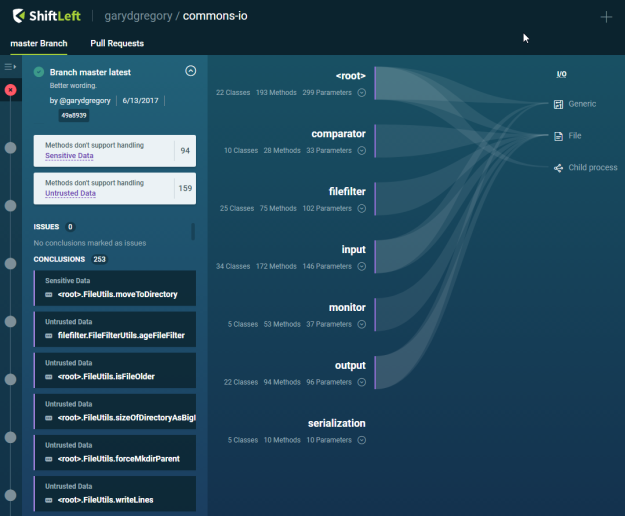
What does it all mean? We have three areas in the UI that we will explore:
- The top-left shows a summary for the current state of the repository’s master branch: the latest commit details and a summary of conclusions (in white boxes.)
- The dark-colored list on the left shows what ShiftLeft calls conclusions. These are our potentially actionable items. As we’ll see, even if you find some conclusions non-actionable, these will do a great deal to raise your awareness of potential security issues for code that you’ll write tomorrow or need to maintain today. You can expand each item (dark box) to reveal more information.
- On the right-hand-side, you see a tree with paths of all public classes organized by package. On the left of that pane is a list of packages. You can expand each package to reveal of the public classes it contains. You can then expand each class to show its methods. We’ll see of this later. Leading away from tree item that have a conclusion, you’ll see light-colored path to its category. In other words, if you see a path leading away from an item, be it a package or class, that means one of its containing items carries with it a conclusion.
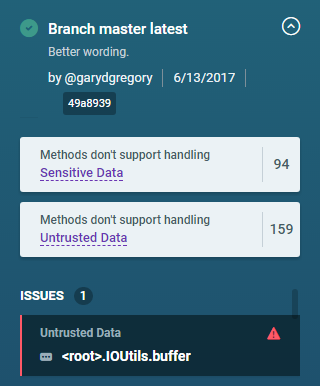
The first thing to notice of course is that I no longer have to consider the whole JSON report file. In the UI, the conclusions are presented in an expandable list without having to filter out the graph data (and thank goodness for that.) There is also a heading called “Issues” you will use to track which conclusions you want to track for changes. Since we’ve not marked any conclusions as issues, the UI presents the expected “0” count and that “No conclusions marked as issues”.
The first UI elements to notice are the two summary boxes for “Sensitive Data” and “Untrusted Data”. ShiftLeft uses these two terms in conclusion descriptions to organize its findings.
The Trusted and Sensitive Kind
Lets describe “Sensitive Data” and “Untrusted Data”.
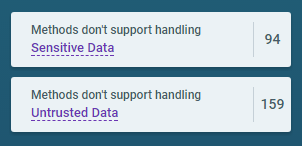
Conclusions described as dealing with Sensitive Data tell you: Lookout, if you have a password in this variable, it’s in plain text. Now, it’s up to me to make sure that this password does not end up in a clear text file or anywhere else that is not secure. This is where context matters, you are the SME of your code, you know how much trouble you can get yourself and your users into, ShiftLeft has no opinion, it offers ‘conclusions.’
Conclusions referring to Untrusted Data: This tells me I should take precautions before doing anything with that data. Should I just execute this script? Should I need to worry about JSON Hijacking? See Why does Google prepend while(1); to their JSON responses?

Looking for Trouble Again
Let’s start with a simple conclusion and get deeper in the weeds after that. When you click on “Sensitive Data” and “Untrusted Data”, you filter the list of conclusions. I choose “Untrusted Data” because I am looking for the first interesting conclusion I found while writing Using ShiftLeft in Open Source: The method IOUtils.buffer(Writer, int) does not support handling untrusted data to be passed as parameter size because it controls the size of a buffer, giving an attacker the chance to starve the system of memory. I find it quickly using a page search:
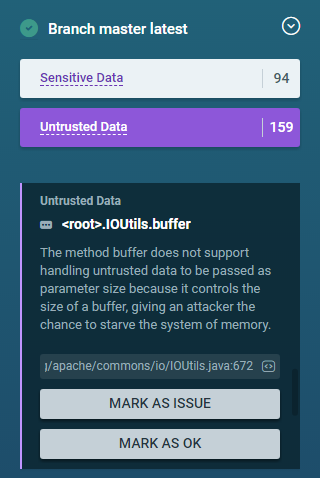
I can click on the link to open a page on exact line of code in GitHub:

While this example may seem trivial, ShiftLeft shows understanding of what the code does in this method: We are allowing call sites to control memory usage in an unbounded manner.
Let’s imagine an application that would allow an unbound value to be used, for example, to process a 2 GB file and that would care about this API and the conclusion rendered by ShiftLeft. To track this conclusion, we mark it as an issue to have it tracked in our Issues list:
Now, for the fun part. Let’s edit the code to guard against unbounded usage. Let’s institute an arbitrary 10 MB limit. We’ll change the code from:
/**
* Returns the given Writer if it is already a {@link BufferedWriter}, otherwise creates a BufferedWriter from the
* given Writer.
*
* @param writer the Writer to wrap or return (not null)
* @param size the buffer size, if a new BufferedWriter is created.
* @return the given Writer or a new {@link BufferedWriter} for the given Writer
* @throws NullPointerException if the input parameter is null
* @since 2.5
*/
public static BufferedWriter buffer(final Writer writer, int size) {
return writer instanceof BufferedWriter ? (BufferedWriter) writer : new BufferedWriter(writer, size);
}
to:
private static final int MAX_BUFFER_SIZE = 10 * 1024 * 1024; // 10 MB
/**
* Returns the given Writer if it is already a {@link BufferedWriter}, otherwise creates a BufferedWriter from the
* given Writer.
*
* @param writer the Writer to wrap or return (not null)
* @param size the buffer size, if a new BufferedWriter is created.
* @return the given Writer or a new {@link BufferedWriter} for the given Writer
* @throws NullPointerException if the input parameter is null
* @since 2.5
*/
public static BufferedWriter buffer(final Writer writer, int size) {
if (size > MAX_BUFFER_SIZE) {
throw new IllegalArgumentException("Request buffer cannot exceed " + MAX_BUFFER_SIZE);
}
return writer instanceof BufferedWriter ? (BufferedWriter) writer : new BufferedWriter(writer, size);
}
After pushing this change to GitHub, I do not see a change in my ShiftLeft report; ah, this is a beta still, should I chalk this up to work in progress or is there still potential trouble ahead?
I wonder if this method shouldn’t be always flagged anyway. Yes, I changed the code so that the memory allocation is no longer unbounded, but who is to decide if my MAX_BUFFER_SIZE is reasonable or not? It might be fine for a simple use case like a single threaded app does does it once. What if I have ten thousand concurrently tasks that want to do this? Is that still reasonable? I’m not so sure. So for now, I think I like being notified of this memory allocation.
Digging deeper
In my previous ShiftLeft post — based on Apache Commons IO 2.5, not master — I had found this conclusion (in raw form edited for brevity):
{
"id": "org.apache.commons.io.FileUtils.copyFileToDirectory:void(java.io.File,java.io.File)/srcFile/2",
"description": "The method `copyFileToDirectory` does not support handling **sensitive data** to be passed as parameter `srcFile` because it is leaked over I/O **File**.",
"unsupportedDataType": "SENSITIVE",
"interfaceId": "FILE/false",
"methodId": "org.apache.commons.io.FileUtils.copyFileToDirectory:void(java.io.File,java.io.File)",
"codeLocationUrl": "https://github.com/apache/commons-io/blob/commons-io-2.5/src/main/java/org/apache/commons/io/FileUtils.java#L1141",
"state": "NEUTRAL",
"externalIssueUrl": "https://todo"
}
Looking at the methodId tells us to go look at FileUtils.copyFileToDirectory(File, File) where we find:
/**
* Copies a file to a directory preserving the file date.
*
* This method copies the contents of the specified source file
* to a file of the same name in the specified destination directory.
* The destination directory is created if it does not exist.
* If the destination file exists, then this method will overwrite it.
*
* <strong>Note:</strong> This method tries to preserve the file's last
* modified date/times using {@link File#setLastModified(long)}, however
* it is not guaranteed that the operation will succeed.
* If the modification operation fails, no indication is provided.
*
* @param srcFile an existing file to copy, must not be {@code null}
* @param destDir the directory to place the copy in, must not be {@code null}
*
* @throws NullPointerException if source or destination is null
* @throws IOException if source or destination is invalid
* @throws IOException if an IO error occurs during copying
* @see #copyFile(File, File, boolean)
*/
public static void copyFileToDirectory(final File srcFile, final File destDir) throws IOException {
copyFileToDirectory(srcFile, destDir, true);
}
This method just delegates to another copyFileToDirectory() with an added parameter, no big deal. What is interesting is that the codeLocationUrl points to code not in this method but to a private utility method:
FileUtils at line 1141 is in the guts of a private method called org.apache.commons.io.FileUtils.doCopyFile(File, File, boolean) which is where ShiftLeft flagged an issue where the method creates a new FileInputStream. Because ShiftLeft is working with a code graph, when I search the JSON conclusions for this URL, I find a total of 14 conclusions that use this URL. This tells me that this code fragment creates 14 possible vulnerabilities in the component; with a careful emphasis on possible since context is important.
If I search in the Conclusions list on the left f the page, I find several hits for “FileUtils.copyFileToDirectory”. Then, I can click to expand each one so see the exact location and hyperlink to GitHub. What I hope is coming is the ability to filter sort so I create a mental picture like I was able with the JSON report.
ShiftLeft also has a user friendly way to discover this information: the tree view:
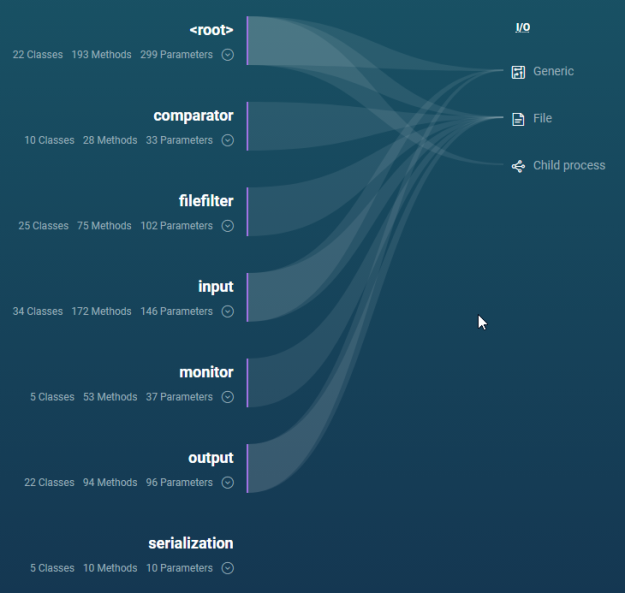
In this view, the “” node is the topmost package in Apache Commons IO. You can see that it has a path that leads to all three different categories: Generic, File, and Child process. This means that the root package contains conclusions and that these conclusions are in the linked categories.
When I expand the root node, I find the FileUtils class (highlighted):
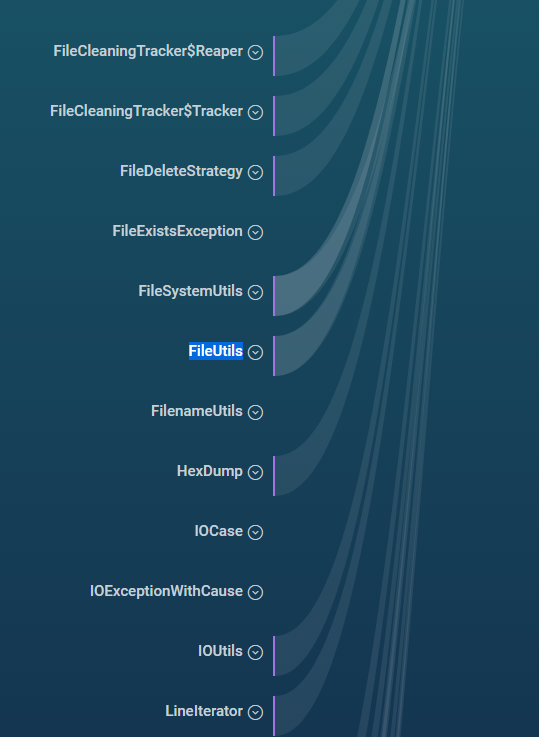
You can see that the class has a path leading away from it, so I know it contains conclusions. At that point, it’s a little harder to make sense of the categories as they’ve scrolled off the top of the screen. It would be nice if the categories floated down as you scroll. Version 2 I hope! You can also see that some classes like FilenameUtils and IOCase do not have paths leading away from them and therefore do not carry conclusions. A relief I suppose, but I’d like to ability to filter out items that are conclusion-free.
I now expand the FileUtils class:

Here, some methods have paths, some don’t; scrolling down, we get to copyFileToDirectory:

As expected, the method has a path leading away from it which indicates a conclusion but we do not know which kind or which one. We do get a description of its parameters though, a nice touch.
For now, clicking on the method does not do anything where I would expect to be able perform the same operations as in the list. This view lets you explore the whole library but I do not find it terribly useful beyond the path to categories. I’d like to see hyperlinks to code and also the use of color to distinguish which methods are flagged as Untrusted Data and Sensitive Data as well as an indication as to which categories are involved that does not scroll of the screen.
The nice thing though is that I have two paths of exploration in the UI: the conclusion list and the explorer tree.
There are two key technologies at work here and that I expect both to get better as the beta progresses: First, building a code graph to give us the power to see that once a problem has been identified on a line of code, that all (I assume public) call-sites can be flagged. Second, what constitutes a problem or a conclusion in ShiftLeft’s neutral parlance will improve and be configurable, filterable and sortable.
In this example, the conclusion description reads:
The method `copyFileToDirectory` does not support handling **sensitive data** to be passed as parameter `srcFile` because it is leaked over I/O **File**.
What goes through my head when I read that is: Yeah, I do not want just anybody to be able to copy any file anywhere like overwriting a password vault a la copyFileToDirectory(myFile, "/etc/shadow"). Granted, Apache Commons IO is a library, not an application, so there is no alarm bells to ring here, but you get the idea.
Stepping back, I think it is important to reiterate what happened here: ShiftLeft found an issue (less dramatic than a problem) on a line of code in a private methods, then, using its code graph, created conclusions (report items) for each public facing method that may eventually call this private method in its code path.
Working from a baseline
If you think that having a list over 200 hundred conclusions to sift through is daunting, I would agree with you. This is why I look forward to using some sorting and filtering in the UI!
What matters just as much is how to use ShiftLeft when your code evolves. I want to track differences from commit to commit and from build to build: Did I create or squash vulnerabilities? This I can tell by watching the Conclusions and Issues list in the UI. I am hoping that ShiftLeft will implement a similar feature to Coveralls where you get an email that tells how much your test code coverage has changed in a build.
As an experiment, let’s see what happens when I add some possibly malicious code, a method to delete all files and directories from a given directory:
package org.apache.commons.io;
import java.io.File;
import java.io.IOException;
public class ADangerousClass {
public void deleteAll(File directory) throws IOException {
FileUtils.deleteDirectory(directory);
}
}
Note that all this method does is delegate to another method. I hit refresh in my browser and I see my commit:
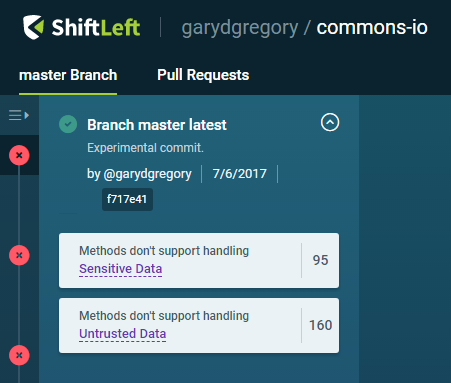
My commit comment, date, and commit hash are there. ShiftLeft goes to work for about two minutes (the two counts are reset to 0 as ShiftLeft is analyzing.) Then the Sensitive Data and Untrusted Data conclusion counts have gone up. Scrolling down I see my new class:
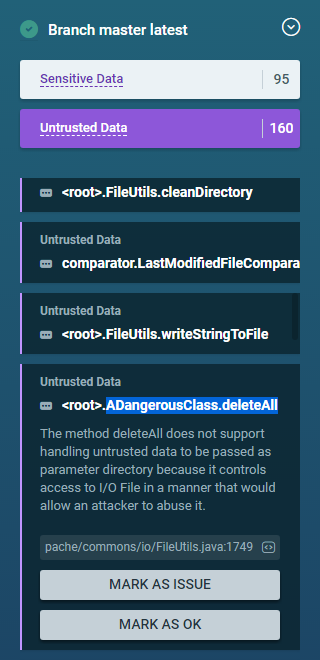
I also see it in the tree of course:
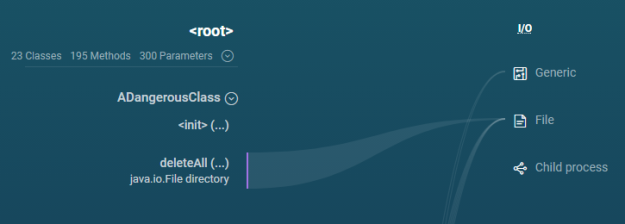
Notice that the deleteAll method has a path to the File category on the right hand side, this makes sense based on my previous findings.
Now I really want to click on the categories on the right as filters! I am especially intrigued by the “Child process” category.
What is worth noting here is that my new class and method do not in themselves actually do anything dangerous. But since we are working with a code graph, and that graph leads to a dangerous place, the new code is flagged.
Now for a bit of fun, let’s change the method to make the dangerous bits unreachable:
public void deleteAll(File directory) throws IOException {
if (false) {
FileUtils.deleteDirectory(directory);
}
}
The dangerous class is gone from the list but present in the tree since it is a public API. What if it’s something more tricky? Let’s make some code unreachable through a local variable, and we will make it final to make it obvious to the code graph that the value is immutable:
public void deleteAll(File directory) throws IOException {
final boolean test = 1 == 2;
if (test) {
FileUtils.deleteDirectory(directory);
}
}
The dangerous class is still gone from the list. Pretty clever it is. Let’s see about delegating the test to a method:
public void deleteAll(File directory) throws IOException {
final boolean test = test();
if (test) {
FileUtils.deleteDirectory(directory);
}
}
private boolean test() {
return 1 == 2;
}
ShiftLeft now shows the deleteAll() method in both the Untrusted Data and Sensitive Data lists. So that’s a false positive. Let’s get away from using a method and use two local variables instead:
public void deleteAll(File directory) throws IOException {
final Object obj = null;
boolean test = true;
if (obj == null) {
test = false;
}
if (test) {
FileUtils.deleteDirectory(directory);
}
}
With this change, ShilfLeft still puts the method as Untrusted Data and Sensitive Data lists. OK, so this is a bit like Eclipse’s compiler warnings for null analysis, it flags what it can see without really evaluating, fair enough.
Linking to the root cause
Let’s go back to the conclusions list for a minute. My deleteAll experiment created two conclusions: one untrusted data, one senstive data. Let’s take a closer look at these.
Untrusted Data
.ADangerousClass.deleteAll
The method
deleteAlldoes not support handling untrusted data to be passed as parameterdirectorybecause it controls access to I/O File in a manner that would allow an attacker to abuse it.
When I click on the GitHub link for Untrusted Data, I see:
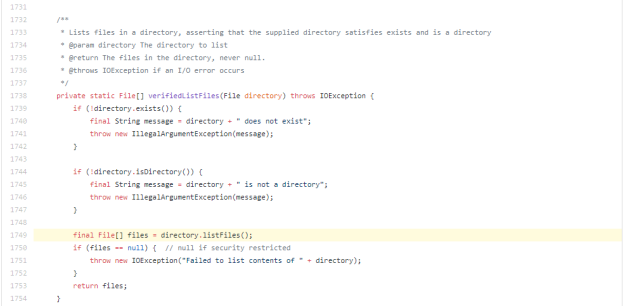
Note that we are not in the deleteAll method here, rather we are where the ShiftLeft code graph flags as the root issue. In other words, if I wrote a public method that called deleteAll, I would get the same conclusion and link. Graph Power!
Why is calling directory.listFiles() labeled untrusted? Well, passing a sensitive file path should not be considered a problem, because the file path you are searching for would not end up written on the disk. It is however considered dangerous if attackers were to control the input path, because they could be able to list arbitrary directories on the system. That’s a breach.
Only considering the method verifiedListFiles(), ShiftLeft does not know that the method is used in an operation to delete files. That’s up next:
Sensitive DataThe methoddeleteAlldoes not support handling sensitive data to be passed as parameterdirectorybecause it is leaked over I/O File.
When I click on the GitHub link for Sensitive Data, I see:
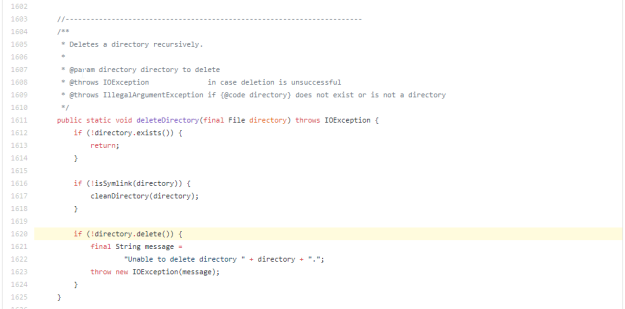
Clearly calling File.delete() can be trouble but using the sensitive data category may be a bit of a stretch. If any sensitive data is used in a file operation, (for example, as the path of the file, like “path/to/my-secrets”,) then that data will end up on disk. For a delete operation, you could say that that’s not the case because you’re doing the reverse, but actually just the fact that you are deleting a file with a sensitive name is interesting. It’s also possible that you already had previously written sensitive data unencrypted to the disk. That’s a roundabout way to get there but it feels justifiable.
Finding arbitrary code attacks
When I first ran ShiftLeft on Apache Commons 2.5, I found a few conclusions for arbitrary code attacks in the Java7Support class. Now that Apache Commons in Git master requires Java 7, the Java7Support class is gone. At the moment, I’ve not found a way to run ShiftLeft on anything but the master branch of a repository, so let’s make our own trouble with Method.invoke() to call BigInteger.intValueExact() on Java 8 and intValue() on older versions of Java:
package org.apache.commons.io;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
import java.math.BigInteger;
public class BigIntHelper {
private static Method intValueExactMethod;
static {
try {
intValueExactMethod = BigInteger.class.getMethod("intValueExact");
} catch (NoSuchMethodException | SecurityException e) {
intValueExactMethod = null;
e.printStackTrace();
}
}
public static int getExactInt(BigInteger bigInt) {
try {
return (int) (intValueExactMethod != null
? intValueExactMethod.invoke(bigInt)
: bigInt.intValue());
} catch (IllegalAccessException | IllegalArgumentException | InvocationTargetException e) {
e.printStackTrace();
return bigInt.intValue();
}
}
public static void main(String[] args) {
System.out.println(getExactInt(BigInteger.TEN));
}
}
This code is OK by ShiftLeft even though our intValueExactMethod variable is private but not final:

Let’s open things up by making the variable by changing:
private static Method intValueExactMethod;
to:
public static Method intValueExactMethod;
For the Java7Support class in Apache Commons 2.5, ShiftLeft reports several arbitrary code attack vulnerabilities. Unfortunately, ShiftLeft does not report any such vulnerabilities for this example. Growing pains I suppose. Well, that’s all I have for now. A fun exploration in an area I’d like to get back to soon.
Fin
 I’d like to wrap up this exploration of ShiftLeft with a quick summary of what we found: a tool we can add to our build pipelines to find potential security vulnerabilities.
I’d like to wrap up this exploration of ShiftLeft with a quick summary of what we found: a tool we can add to our build pipelines to find potential security vulnerabilities.
There are a lot of data here, and this is just for Apache Commons IO! Another lesson is that context matters. This is low-level library as opposed to an application. Finding vulnerabilities in a low level library is good but this may not be vulnerabilities for your application. ShiftLeft conclusions can at least make you aware of how to use this library safely. ShiftLeft currently provides conclusions based on a code graph, this is powerful, as the examples show. We found conclusions about untrusted data (I’m not sure what’s in here so don’t go executing it) and sensitive data (don’t save passwords in plain text!)
I hope revisit this story and run ShiftLeft on other Apache Commons projects soon. This sure is fun!
Happy Coding,
Gary Gregory

 Tangent: What could you do in this case? You could hard-code an upper bound of say 10 MB. You could make the bound configurable with a static non-final variable (effectively creating a global variable, an anti-pattern for sure.) You could move all the static methods to the instance side, create a memory profile class to define this bound, and then build
Tangent: What could you do in this case? You could hard-code an upper bound of say 10 MB. You could make the bound configurable with a static non-final variable (effectively creating a global variable, an anti-pattern for sure.) You could move all the static methods to the instance side, create a memory profile class to define this bound, and then build 

 It turns out that
It turns out that  The Good is thin: FindBugs has two committers with push karma: Andrey Loskutov and Tagir Valeev. That’s not much for such a complex project but better than none. Tagir’s last
The Good is thin: FindBugs has two committers with push karma: Andrey Loskutov and Tagir Valeev. That’s not much for such a complex project but better than none. Tagir’s last  Bill Pugh, the project lead, has not been active and is the bottleneck for access rights to critical parts of the project. According to Andrey:
Bill Pugh, the project lead, has not been active and is the bottleneck for access rights to critical parts of the project. According to Andrey: FindBugs has been around for a long time now (ten years) and has accrued a fair amount of technical debt.
FindBugs has been around for a long time now (ten years) and has accrued a fair amount of technical debt.



{kind=link}